
💡说明
https://facebook.github.io/prophet/docs/diagnostics.html
Prophet包括时间序列交叉验证(cross validation)的功能,以使用历史数据测量预测误差。这是通过选择历史上的截止点来实现的,对于每个截止点,只使用到该截止点的数据来拟合模型,然后我们可以将预测值与实际值进行比较。然后我们可以将预测值与实际值进行比较。本图展示了对佩顿-曼宁数据集的模拟历史预测,模型被拟合到5年的初始历史中,并在一年的时间范围内进行预测。
png
Prophet论文对模拟历史预测做了进一步的描述。
这个交叉验证过程可以使用cross_validation函数对一系列历史截止日期自动完成。我们指定预测范围(horizon),然后选择初始训练期的大小(initial)和截止日期之间的间隔(period)。默认情况下,初始训练期设置为horizon的三倍,每半个horizon进行一次截断。
cross_validation的输出是一个dataframe,其中包括每个模拟预测日期和每个截止日期的真实值y和样本外预测值yhat。特别地,对 cutoff 和 cutoff + horizon之间的每个观测点进行预测。然后,可利用这一数据框架计算 yhat与 y的误差测量。
.
在这里,我们做交叉验证来评估365天的horizon上的预测性能,从第一个截止点的730天的训练数据开始,然后每180天做一次预测。在这个8年的时间序列上,这相当于11次总的预测。
# Rdf.cv <- cross_validation(m, initial = 730, period = 180, horizon = 365, units = 'days')head(df.cv)
# Pythonfrom fbprophet.diagnostics import cross_validationdf_cv = cross_validation(m, initial='730 days', period='180 days', horizon = '365 days')
# Pythondf_cv.head()
在R中,参数 units 必须是as.difftime接受的类型,即周或更短。在Python中,initial, period 和 horizon 的字符串应该是Pandas Timedelta使用的格式,它接受天或更短的单位。
自定义截止日期也可以以日期列表的形式提供给Python和R中cross_validation函数中的cutoffs关键字,例如,三个截止日期相隔6个月,需要传递给cutoffs参数,日期格式如下:
# Rcutoffs <- as.Date(c('2013-02-15', '2013-08-15', '2014-02-15'))df.cv2 <- cross_validation(m, cutoffs = cutoffs, horizon = 365, units = 'days')
# Pythoncutoffs = pd.to_datetime(['2013-02-15', '2013-08-15', '2014-02-15'])df_cv2 = cross_validation(m, cutoffs=cutoffs, horizon='365 days')
performance_metrics实用程序可用于计算预测性能的一些有用统计数据(yhat、yhat_lower和yhat_upper与y相比),作为与截止点的距离(预测在未来多远)的函数。计算的统计数字是平均平方误差(MSE)、平均平方根误差(RMSE)、平均绝对误差(MAE)、平均绝对百分比误差(MAPE)、中位绝对百分比误差(MDAPE)和yhat_lower和yhat_upper估计的覆盖率。这些都是在按地平线排序(ds减cutoff)后,在df_cv中的预测的滚动窗口上计算的。默认情况下,每个窗口将包括10%的预测,但可以用rolling_window参数改变。
# Rdf.p <- performance_metrics(df.cv)head(df.p)
# Pythonfrom fbprophet.diagnostics import performance_metricsdf_p = performance_metrics(df_cv)df_p.head()
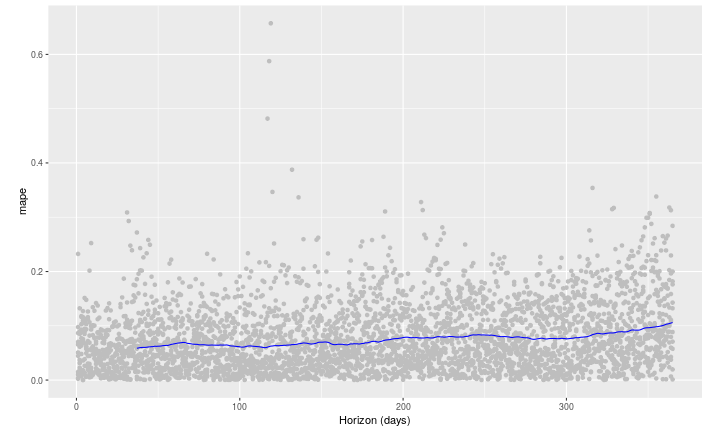
交叉验证性能指标可以用plot_cross_validation_metric进行可视化,这里显示的是MAPE。点表示df_cv中每个预测的绝对误差百分比。蓝线显示的是MAPE,其中平均值是在点的滚动窗口上取的。我们看到,对于这种预测,对于未来一个月的预测,典型的误差是5%左右,对于一年后的预测,误差增加到11%左右。
# Rplot_cross_validation_metric(df.cv, metric = 'mape')
# Pythonfrom fbprophet.plot import plot_cross_validation_metricfig = plot_cross_validation_metric(df_cv, metric='mape')
png
图中滚动窗口的大小可以通过可选的参数rolling_window来改变,它指定了每个滚动窗口中使用的预测比例。默认值是0.1,相当于每个窗口中包含的 df_cv行的10%;增加这个比例将使图中的平均曲线更加平滑。initial 期应该足够长,以捕获模型的所有组成部分,特别是季节性因素和额外的回归因子:年季节性至少一年,周季节性至少一周,等等。
交叉验证也可以在Python中以并行模式运行,通过设置指定parallel关键字。支持四种模式
parallel=None (默认情况下,没有并行)parallel="processes"parallel="threads"parallel="dask"对于不太大的问题,我们建议使用parallel="process"。如果能在一台机器上完成并行交叉验证,将达到最高性能。对于大型问题,可以使用Dask集群在多台机器上进行交叉验证。你需要单独安装Dask,因为它不会和fbprophet一起安装。
from dask.distributed import Clientclient = Client() # connect to the clusterdf_cv = cross_validation(m, initial='730 days', period='180 days', horizon='365 days', parallel="dask")
交叉验证可用于调整模型的超参数,如 changepoint_prior_scale 和 seasonality_prior_scale。下面给出了一个Python例子,这两个参数的网格为4x4,在截止点上进行并行化。这里的参数是以30天范围内的RMSE平均值来评估的,但不同的性能指标可能适合不同的问题。
# Pythonimport itertoolsimport numpy as npimport pandas as pdparam_grid = { 'changepoint_prior_scale': [0.001, 0.01, 0.1, 0.5], 'seasonality_prior_scale': [0.01, 0.1, 1.0, 10.0],}# Generate all combinations of parametersall_params = [dict(zip(param_grid.keys(), v)) for v in itertools.product(*param_grid.values())]rmses = [] # Store the RMSEs for each params here# Use cross validation to evaluate all parametersfor params in all_params: m = Prophet(**params).fit(df) # Fit model with given params df_cv = cross_validation(m, cutoffs=cutoffs, horizon='30 days', parallel="processes") df_p = performance_metrics(df_cv, rolling_window=1) rmses.append(df_p['rmse'].values[0])# Find the best parameterstuning_results = pd.DataFrame(all_params)tuning_results['rmse'] = rmsesprint(tuning_results)
changepoint_prior_scale seasonality_prior_scale rmse
0 0.001 0.01 0.757489
1 0.001 0.10 0.745049
2 0.001 1.00 0.753315
3 0.001 10.00 0.763111
4 0.010 0.01 0.536260
5 0.010 0.10 0.538103
6 0.010 1.00 0.544326
7 0.010 10.00 0.520970
8 0.100 0.01 0.524669
9 0.100 0.10 0.521302
10 0.100 1.00 0.520692
11 0.100 10.00 0.515338
12 0.500 0.01 0.532103
13 0.500 0.10 0.528939
14 0.500 1.00 0.525256
15 0.500 10.00 0.524619
# Pythonbest_params = all_params[np.argmin(rmses)]print(best_params)
{'changepoint_prior_scale': 0.1, 'seasonality_prior_scale': 10.0}
另外,也可以通过上面的循环并行化来实现跨参数组合的并行化。
Prophet模型有许多输入参数,可以考虑对其进行调整。下面是一些超参数调整的一般建议,可能不错呦。
可调整的参数
changepoint_prior_scale: 这可能是影响最大的参数。它决定了趋势的灵活性,特别是趋势变化点的趋势变化程度。正如本文档中所描述的,如果它太小,趋势将被欠拟合,而本应该用趋势变化来建模的方差最终将用噪声项来处理。如果太大,趋势将过度拟合,在最极端的情况下,你可能最终会让趋势捕捉到每年的季节性。0.05的默认值适用于许多时间序列,但可以进行调整;[0.001, 0.5]的范围可能是正确的。像这样的参数(regularization penalties;这实际上是一种套lasso penalty)通常在对数范围内进行调整。seasonality_prior_scale: 同样,大值可以让季节性适应大的波动,小值可以缩小季节性的幅度。默认值是10.,基本不应用正则化。这是因为我们很少在这里看到过拟合(there’s inherent regularization with the fact that it is being modeled with a truncated Fourier series, so it’s essentially low-pass filtered)。一个合理的调整范围可能是[0.01,10];当设置为0.01时,你应该会发现季节性的幅度被迫变得非常小。这在对数尺度上可能也是有意义的,因为它实际上是一个L2 penalty,就像在ridge regression中一样。holidays_prior_scale: 这控制了拟合假日效应的灵活性。与 seasonality_prior_scale 类似,它的默认值是 10.0,基本上不需要正则化,因为我们通常有多个节假日的观测值,可以很好地估计它们的影响。这也可以像季节性_prior_scale那样在[0.01, 10]的范围内进行调整。seasonality_mode: 选项为['additive', 'multiplicative']。默认值是 'additive',但许多商业时间序列将具有多重季节性。最好的办法是通过观察时间序列,看季节性波动的幅度是否随时间序列的幅度而增长(见这里关于多重季节性的文档),但如果无法做到这一点,可以对其进行调整。也许可以调整的参数
changepoint_range: 这是历史情况上允许趋势变化的比例,默认为0.8,即历史的80%,这意味着模型不会拟合时间序列最后20%的趋势变化。默认值为0.8,即历史的80%,这意味着模型不会拟合时间序列最后20%的趋势变化。这是相当保守的做法,以避免在时间序列的末尾对趋势变化进行过度拟合,因为在那里没有足够的runway 可以很好地拟合。如果有一个人在循环中,这是很容易被视觉识别的事情:人们可以很清楚地看到预测是否在最后20%做得不好。在完全自动化的环境中,不那么保守可能是有益的。如上所述,很可能无法在截止点上通过交叉验证来有效地调整这个参数。从时间序列最后10%的趋势变化中归纳出模型的能力,将很难从观察早期的截止点了解到最后10%可能没有趋势变化。所以,这个参数可能最好不要调整,除非可能是在大量的时间序列上。在这种情况下,[0.8,0.95]可能是一个合理的范围。可能不要被调整的参数
growth: 选项是 “线性”和 “逻辑”。这很可能不要被调整;如果有一个已知的饱和点和朝向该点的增长,它将被包括在内,并将使用逻辑趋势,否则它将是线性的。changepoints: 这是用于手动指定变更点的位置。默认情况下为 “无”,会自动放置。n_changepoints: 这是自动放置的变化点的数量。默认的25个应该足以捕捉典型时间序列的趋势变化(至少是Prophet可以很好地工作的类型)。与其增加或减少变化点的数量,不如专注于增加或减少这些趋势变化的灵活性,这可能会更有效,这可以通过changepoint_prior_scale来实现。yearly_seasonality: .默认情况下(‘auto’),如果有一年的数据,将开启年度季节性,否则关闭。选项是[‘auto’, True, False]。如果有超过一年的数据,与其在HPO时关闭它,不如让它开启,并通过调整seasonality_prior_scale来降低季节性影响。weekly_seasonality: 和 yearly_seasonality 一样。daily_seasonality:和 yearly_seasonality 一样holidays: 这是为了传递一个指定假期的dataframe 。假日效果将用holidays_prior_scale进行调整。mcmc_samples: 是否使用MCMC将可能由时间序列的长度和参数不确定性的重要性等因素决定(这些考虑因素在文档中有所描述)。interval_width: Prophet predict返回每个分量的不确定性区间,如预测yhat的yhat_lower和yhat_upper。这些区间是以后验预测分布的量子数计算的,interval_width指定了要使用的量子数。默认的0.8提供了80%的预测区间。如果你想要95%的区间,可以改成0.95。这将只影响不确定性区间,根本不会改变预测yhat,因此不需要调整。uncertainty_samples: 不确定性区间是以后预测区间的量子值计算的,后预测区间是用蒙特卡洛抽样估计的。这个参数是要使用的样本数(默认为1000)。预测的运行时间将与这个数字呈线性关系。把它变小会增加不确定性区间的方差(蒙特卡洛误差),把它变大则会减少方差。所以,如果不确定度估计看起来是锯齿状的,可以增加这个数字来进一步平滑它们,但很可能不需要改变。和 interval_width一样,这个参数只影响不确定性区间,改变它不会以任何方式影响预测的 yhat,它不需要调整。stan_backend: 如果同时设置了pystan和cmdstanpy set up,,可以指定后台。预测会是一样的,这个不会被调整。